01. Introduction
Introduction
Deep convolutional neural networks (CNNs) have demonstrated to be very effective at image classification and object detection in images. It turns out that the same principles and architectures can be extended to three dimensions to create deep 3-dimensional convolutional neural networks (3D CNNs). These 3D CNNs are suitable for video analysis because we can use 2 dimensions to handle spatial features and the third dimension to handle temporal features. In this regard, 3D CNNs are just like standard convolutional networks, except that they use spatio-temporal filters, instead of just spatial filters. The figure below shows a schematic diagram of a 3D CNN
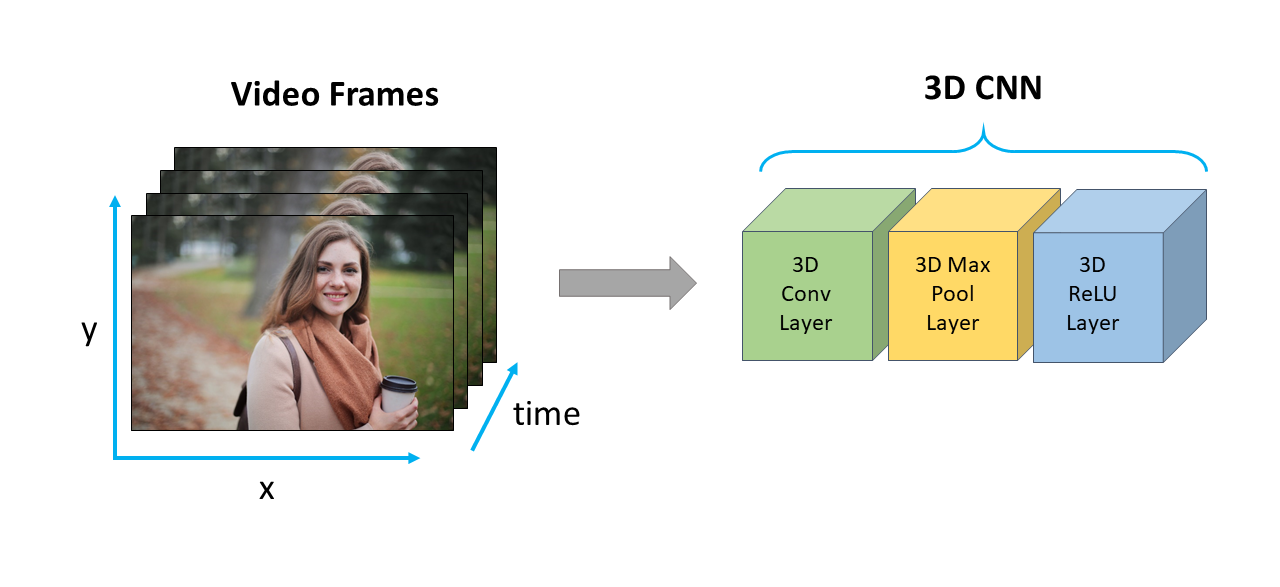
Because these 3D CNNs can capture temporal features, they can be used to detect and recognize actions in videos. In this lesson, we will see how we can train a 3D CNN to learn to recognize hand gestures in videos.